B tree vs B+ tree
Before understanding B tree and B+ tree differences, we should know the B tree and B+ tree separately.
What is the B tree?
B tree is a self-balancing tree, and it is a m-way tree where m defines the order of the tree. Btree is a generalization of the Binary Search tree in which a node can have more than one key and more than two children depending upon the value of m. In the B tree, the data is specified in a sorted order having lower values on the left subtree and higher values in the right subtree.
Properties of B tree
The following are the properties of the B tree:
- In the B tree, all the leaf nodes must be at the same level, whereas, in the case of a binary tree, the leaf nodes can be at different levels.
Let’s understand this property through an example.
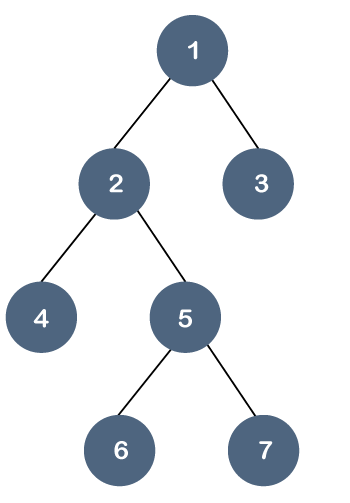
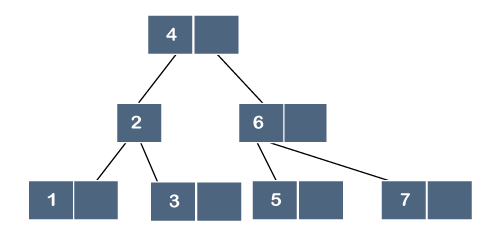
In the above tree, all the leaf nodes are not at the same level, but they have the utmost two children. Therefore, we can say that the above tree is a binary tree but not a B tree.
- If the Btree has an order of m, then each node can have a maximum of m In the case of minimum children, the leaf nodes have zero children, the root node has two children, and the internal nodes have a ceiling of m/2.
- Each node can have maximum (m-1) keys. For example, if the value of m is 5 then the maximum value of keys is 4.
- The root node has minimum one key, whereas all the other nodes except the root node have (ceiling of m/2 minus – 1) minimum keys.
- If we perform insertion in the B tree, then the node is always inserted in the leaf node.
Suppose we want to create a B tree of order 3 by inserting values from 1 to 10.
Step 1: First, we create a node with 1 value as shown below:

Step 2: The next element is 2, which comes after 1 as shown below:

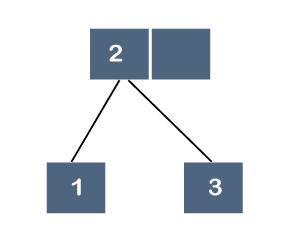
Step 3: The next element is 3, and it is inserted after 2 as shown below:

As we know that each node can have 2 maximum keys, so we will split this node through the middle element. The middle element is 2, so it moves to its parent. The node 2 does not have any parent, so it will become the root node as shown below:
Step 4: The next element is 4. Since 4 is greater than 2 and 3, so it will be added after the 3 as shown below:
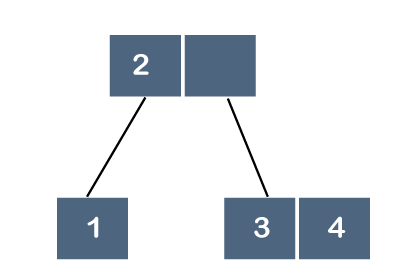
Step 5: The next element is 5. Since 5 is greater than 2, 3 and 4 so it will be added after 4 as shown below:
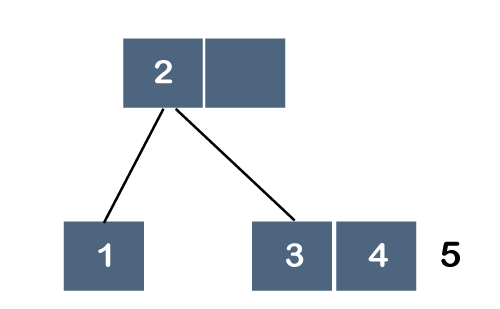
As we know that each node can have 2 maximum keys, so we will split this node through the middle element. The middle element is 4, so it moves to its parent. The parent is node 2; therefore, 4 will be added after 2 as shown below:
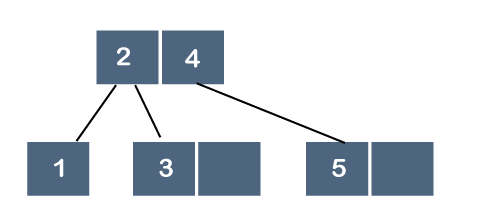
Step 6: The next element is 6. Since 6 is greater than 2, 4 and 5, so 6 will come after 5 as shown below:
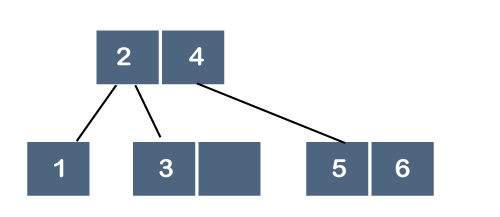
Step 7: The next element is 7. Since 7 is greater than 2, 4, 5 and 6, so 7 will come after 6 as shown below:
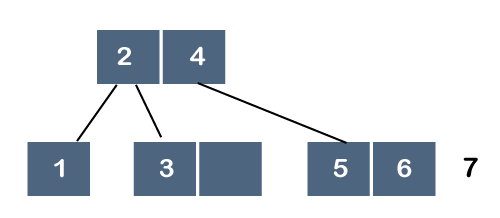
As we know that each node can have 2 maximum keys, so we will split this node through the middle element. The middle element is 6, so it moves to its parent as shown below:
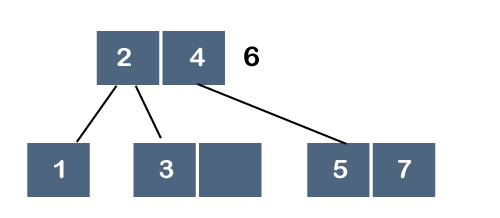
But, 6 cannot be added after 4 because the node can have 2 maximum keys, so we will split this node through the middle element. The middle element is 4, so it moves to its parent. As node 4 does not have any parent, node 4 will become a root node as shown below:
What is a B+ tree?
The B+ tree is also known as an advanced self-balanced tree because every path from the root of the tree to the leaf of the tree has the same length. Here, the same length means that all the leaf nodes occur at the same level. It will not happen that some of the leaf nodes occur at the third level and some of them at the second level.
A B+ tree index is considered a multi-level index, but the B+ tree structure is not similar to the multi-level index sequential files.
Why is the B+ tree used?
A B+ tree is used to store the records very efficiently by storing the records in an indexed manner using the B+ tree indexed structure. Due to the multi-level indexing, the data accessing becomes faster and easier.
B+ tree Node Structure
The node structure of the B+ tree contains pointers and key values shown in the below figure:

As we can observe in the above B+ tree node structure that it contains n-1 key values (k1 to kn-1) and n pointers (p1 to pn).
The search key values which are placed in the node are kept in sorted order. Thus, if i<j then ki<kj.
Constraint on various types of nodes
Let ‘b’ be the order of the B+ tree.
Non-Leaf node
Let ‘m’ represents the number of children of a node, then the relation between the order of the tree and the number of children can be represented as:

Let k represents the search key values. The relation between the order of the tree and search key can be represented as:
As we know that the number of pointers is equal to the search key values plus 1, so mathematically, it can be written as:
Number of Pointers (or children) = Number of Search keys + 1
Therefore, the maximum number of pointers would be ‘b’, and the minimum number of pointers would be the ceiling function of b/2.
Leaf Node
A leaf node is a node that occurs at the last level of the B+ tree, and each leaf node uses only one pointer to connect with each other to provide the sequential access at the leaf level.
In leaf node, the maximum number of children is:
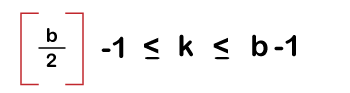
The maximum number of search keys is:
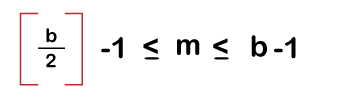
Root Node
The maximum number of children in the case of the root node is: b
The minimum number of children is: 2
Special cases in B+ tree
Case 1: If the root node is the only node in the tree. In this case, the root node becomes the leaf node.
In this case, the maximum number of children is 1, i.e., the root node itself, whereas, the minimum number of children is b-1, which is the same as that of a leaf node.
Representation of a leaf node in B+ tree
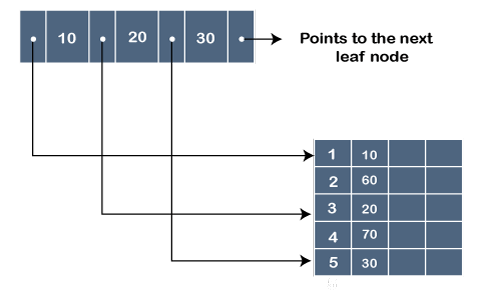
In the above figure, ‘.’ represents the pointer, whereas the 10, 20 and 30 are the key values. The pointer contains the address at which the key value is stored, as shown in the above figure.
Example of B+ tree
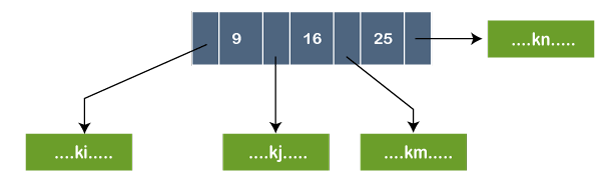
In the above figure, the node contains three key values, i.e., 9, 16, and 25. The pointer that appears before 9, contains the key values less than 9 represented by ki. The pointer that appears before 16, contains the key values greater than or equal to 9 but less than 16 represented by kj. The pointer that appears before 25, contains the key values greater than or equal to 16 but less than 25 represented by kn.
Differences between B tree and B+ tree

The following are the differences between the B tree and B+ tree:
| B tree | B+ tree |
|---|---|
| In the B tree, all the keys and records are stored in both internal as well as leaf nodes. | In the B+ tree, keys are the indexes stored in the internal nodes and records are stored in the leaf nodes. |
| In B tree, keys cannot be repeatedly stored, which means that there is no duplication of keys or records. | In the B+ tree, there can be redundancy in the occurrence of the keys. In this case, the records are stored in the leaf nodes, whereas the keys are stored in the internal nodes, so redundant keys can be present in the internal nodes. |
| In the Btree, leaf nodes are not linked to each other. | In B+ tree, the leaf nodes are linked to each other to provide the sequential access. |
| In Btree, searching is not very efficient because the records are either stored in leaf or internal nodes. | In B+ tree, searching is very efficient or quicker because all the records are stored in the leaf nodes. |
| Deletion of internal nodes is very slow and a time-consuming process as we need to consider the child of the deleted key also. | Deletion in B+ tree is very fast because all the records are stored in the leaf nodes so we do not have to consider the child of the node. |
| In Btree, sequential access is not possible. | In the B+ tree, all the leaf nodes are connected to each other through a pointer, so sequential access is possible. |
| In Btree, the more number of splitting operations are performed due to which height increases compared to width, | B+ tree has more width as compared to height. |
| In Btree, each node has atleast two branches and each node contains some records, so we do not need to traverse till the leaf nodes to get the data. | In B+ tree, internal nodes contain only pointers and leaf nodes contain records. All the leaf nodes are at the same level, so we need to traverse till the leaf nodes to get the data. |
| The root node contains atleast 2 to m children where m is the order of the tree. | The root node contains atleast 2 to m children where m is the order of the tree. |