Boot Block and Bad Block in Operating System
The operating system is responsible for several other features of disk management, such as disk initialization, boot block or booting from disk, and bad block. A boot block is a region of a hard disk, floppy disk, optical disc, or other data storage device that contains machine code to be loaded into random-access memory (RAM) by a computer system’s built-in firmware.
And a bad block is a sector on a computer’s disk drive or a flash memory that cannot be used due to permanent damage, such as physical damage to the disk surface or failed flash memory transistors.
What is Boot Block in Operating System?
When a computer starts running or reboots to get an instance, it needs an initial program to run. This initial program is known as the bootstrap program, and it must initialize all aspects of the system, such as:
- First, initializes the CPU registers, device controllers, main memory, and then starts the operating system.
- The bootstrap program finds the operating system kernel on disk to do its job and then loads that kernel into memory.
- And last jumps to the initial address to begin the operating-system execution.
The bootstrap is stored in read-only memory (ROM). This location is convenient because ROM needs no initialization, and it is at a fixed location that the processor can start executing when powered up or reset. Since ROM is read-only memory, it cannot be infected by a computer virus. The problem is changing this bootstrap code requires changing the ROM and hardware chips. That’s why systems store a tiny bootstrap loader program in the boot ROM whose job is to bring in a full bootstrap program from disk.
The full bootstrap program can change easily, and a new version is written onto the disk. The full bootstrap program is stored in “the boot blocks“ at a fixed location on the disk. A disk that has a boot partition is called a boot disk or system disk.
In the boot ROM, the code instructs the disk controller to read the boot blocks into memory (no device drivers are loaded at this point) and then starts executing that code. The full bootstrap program is more sophisticated than the bootstrap loader in the boot ROM because it can load the entire operating system from a non-fixed location on a disk and start the operating system running.
How Boot Block Works?
Let’s try to understand this using an example of the boot process in Windows 2000.
The Windows 2000 stores its boot code in the first sector on the hard disk. The following image shows the booting from disk in Windows 2000.
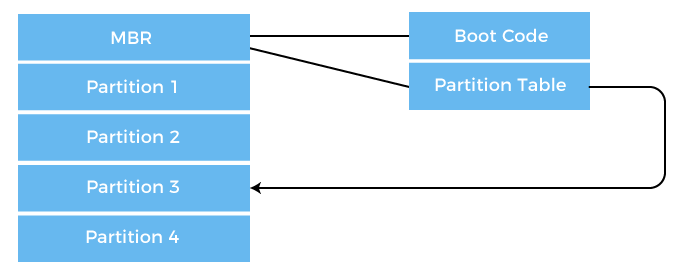
- Moreover, Windows 2000 allows the hard disk to be divided into one or more partitions. This one partition is identified as the boot partition, containing the operating system and the device drivers.
- In Windows 2000, booting starts by running the code placed in the system’s ROM memory.
- This code allows the system to read code directly from the master boot record or MBR.
- The MBR also contains the table that lists the partition for the hard disk and a flag indicating which partition is to be boot from the system.
- Once the system identifies the boot partition, it reads the first sector from memory, known as a boot sector. It continues the process with the remainder of the boot process, which includes loading various system services.
What is Bad Block in Operating System?
A bad block is an area of storage media that is no longer reliable for storing and retrieving data because it has been completely damaged or corrupted. Bad blocks are also referred to as bad sectors.
We know disks have moving parts and have small tolerances. They are prone to failure. When the failure is complete, the disk needs to be replaced and its contents restored from backup media to the new disk. More frequently, one or more sectors become defective.
Types of Bad Blocks
There are two types of bad blocks in the operating system, such as:

- Physical or Hard Bad Block: It comes from damage to the storage medium.
- Logical or Soft Bad Block: It occurs when the operating system cannot read data from a sector.
For example, it occurs when the cyclic redundancy check (CRC) or error correction code (ECC) for a particular storage block and then does not match the data read by the disk.
Causes of Bad Block
Storage drives can ship from the factory with defective blocks that originated in the manufacturing process. The device with bad blocks is marked as defective before leaving the factory. These are remapped with the available extra memory cells.
Physical damage of a device also makes a bad block device because then the operating system is not able to access the data from the damaged device. Dropping a laptop, dust, and natural wear will also cause damage to the platter of the HDDs.
When the memory transistor fails, it will cause damage to the solid-state drive. Storage cells can also become unreliable over time, as NAND flash substrate in a cell becomes unusable after a certain number of program-erase cycles.
The erase process on the solid-state drive (SSD) requires many electrical charges through the flashcards. This degrades the oxide layer that separates the floating gate transistors from the flash memory silicon substrate and increases bit error rates. The drive’s controller can use error detection and correction mechanisms to fix these errors. However, the errors can outstrip the controller’s ability to correct them at some point, and the cell can become unreliable.
Software problems cause soft bad sectors. For example, if a computer unexpectedly shuts down, the hard drive also turns off in the middle of writing to a block. Due to this, the block could contain data that doesn’t match the CRC detection error code, and then it would be identified as a bad sector.
How Bad Block Works
These blocks are handled in many ways, but it depends upon the disk and controller. Bad blocks are handled manually for some disks with IDE controllers or simple disks.
- The first strategy is to scan the disk to find bad blocks while the disk is being formatted. Any bad block discovered is flagged as unusable so that the file system does not allocate them. If blocks go bad during normal operation, a special program (Linux bad blocks command) must be run manually to search for the bad blocks and stop them away.
- More sophisticated disks are smarter about bad-block recovery. The work of the controller is to maintain the list of bad blocks. The list formed by the controller is initialized during the low-level formatting at the factory and updated over the disk’s life.
Low-level formatting holds the spare sectors which are not visible to the operating system. In the last, a controller replaces each bad sector logically with the spare sectors. This process is also known as sector sparing and forwarding.
Example
In the operating system, a typical bad block transaction follows the following steps:
- Suppose the Operating system wants to read logical block 80.
- Now, the controller will calculate EEC and suppose it found the block as bad, then it reports to the operating system that the requested block is bad.
- Whenever the system is rebooted next time, a special command is used, and it will tell the controller that this sector is to be replaced with the spare sector.
- In future, whenever there is a request for block 80, the request is translated to the replacement sector’s address by the controller.
Replacement of Bad Block
The redirection by the controller could invalidate any optimization by the operating system’s disk-scheduling algorithm. For this reason, most disks are formatted to provide a few spare sectors in each cylinder and spare cylinder. Whenever the bad block will remap, the controller will use a spare sector from the same cylinder, if possible. Otherwise, a spare cylinder is also used.
Some controllers use the spare sector to replace the bad block. There is also another technique to replace the bad block, which is sector slipping.
For example, suppose that logical block 20 becomes defective and the first available spare sector follows sector 200. then sector slipping starts remapping. All the sectors from 20 to 200, moving all down one spot. That sector 200 is copied into the spare, then sector 199 into 200, then 198 into 199, and so on, until sector 21 is copied into sector 22. In this way, slipping the sectors frees up the space of sector 21 so that sector 20 can be mapped to it.
The replacement of the bad block is not automatic because data in the bad block are usually lost. A process is trigger by the soft errors in which a copy of the block data is made, and the block is spared or slipped. A hard error that is unrecoverable will lost all your data. Whatever file was using that block must be repaired, and that requires manual intervention.
Management of Bad Block
The best way to fix an HDD file that has been affected by a bad block is to write over the original file. This will cause the hard disk to remap the bad block or fix the data.
Bad block management is critical to improving NAND flash drive reliability and endurance. All changes must write to a new block, and the data in the original block must be marked for deletion.
- Once a flash drive fills up, the controller must start clearing out blocks marked for deletion before writing new data. After that, it consolidates good data by copying it to a new block. This process requires extra writes to consolidate the good data and results in write amplification where the number of actual writes exceeds the number requested. Write amplification can decrease the performance and life span of a flash drive.
- Flash vendors use many techniques to control write amplification. One, known as garbage collection, involves proactively consolidating data by freeing up previously written blocks. These reallocated sectors can reduce the need to erase entire blocks of data for every write operation.
- Vendors also use data reduction technologies, such as compression and duplication, to minimize the amount of data written and erased on a drive. In addition, an SSD’s interface can help decrease write amplification. Serial ATA’s TRIM and SAS’s UNMAP commands identify data blocks no longer in use that can wipe out. This approach minimizes garbage collection and frees up space on the drive, resulting in better performance.