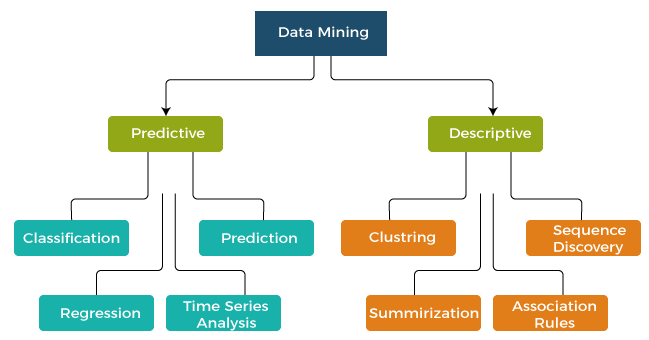
Data Mining Models
Data mining uses raw data to extract information and present it uniquely. The data mining process is usually found in the most diverse range of applications, including business intelligence studies, political model forecasting, web ranking forecasting, weather pattern model forecasting, etc. In business operation intelligence studies, business experts mine huge data sets related to a business operation or a market and try to discover previously unrecognized trends and relationships. Data mining is also used in organizations that utilize big data as a raw data source to extract the required data.
Read on the given article to know the data mining models with examples.
What are data mining models?
A Data mining model refers to a method that usually use to present the information and various ways in which they can apply information to specific questions and problems. As per the specialists, the data mining regression model is the most commonly used data mining model. In this process, a mining expert first analyzes the data sets and creates a formula that defines them. Various Financial market analysts use this model to make predictions related to prices and market trends.
Another significant data mining model is based on the association rule. First, the data mining analysts analyze the data sets to find which components usually appear together. When they find the two components are paired simultaneously, it assumes that there are some relation exits between them. For instance, an electronic shop might find that consumers often purchase a marker and pen simultaneously they purchase a book. A shop manager can use the detailed information from the data mining model to increase sales by presenting all related products at the same place.
Types of data mining models

- Predictive data mining models
- Descriptive data mining models
Predictive data mining models
A predictive data mining model predicts the values of data using known results gathered from the different data sets. Predictive modeling can not be classified as a separate discipline; it occurs in all organizations or industries across all disciplines. The main objective of predictive data mining models is to predict the future based on the past data, generally but not always on the statistical modeling.
Predictive modeling is used in healthcare industries to identify high-risk patients with congestive heart failures, high blood pressure, diabetes, infection, cancer, etc. It is also used in the vehicle insurance company to assign the risk of accidents to the policyholder.
A predictive model of a data mining task comprises classification, regression, prediction, and time series analysis. The predictive model of data mining is also called statistical regression. It refers to a monitoring learning technique that includes an explication of the dependency of a few attribute’s values upon the other attribute’s value in the same product and the growth of a model that can predict these attribute’s values in previous cases.
Classification:
In data mining, classification refers to a form of data analysis where a machine learning model assigns a specific category to a new observation. It is based on what the model has learned from the data sets. In other words, classification is the act of assigning objects to many predefined categories.
One example of classification in the banking and financial services industry is identifying whether transactions are fraudulent or not. In the same way, machine learning can also be used to predict whether a loan application would be approved or not.
Regression:
Regression refers to a method that verifies the value of data for a function. Generally, it is used for appropriate data.
A linear regression model in the context of machine learning or statistics is basically a linear approach for modeling the relationships between the dependent variable known as the result and your independent variable is known as features.
If your model has only one independent variable, it is called simple linear regression, and else it is called multiple linear regression.
Types of regression
1. Linear Regression:
Linear regression is related to the search for the optimal line which fits the two attributes so that with the help of one attribute, we can predict the other.
2. Multi-linear regression
Multi-linear regression includes two or more than two attributes, and the data are fit to multi-dimensional space.
Prediction:
In data mining, prediction is used to identify data value based on the description of another corresponding data value. The prediction in data mining is known as Numeric Prediction. Generally, regression analysis is used for prediction. For example, in credit card fraud detection, data history for a particular person’s credit card usage has to be analyzed. If any abnormal pattern was detected, it should be reported as ‘fraudulent action’.
Time series analysis:
Time series analysis refers to the data sets based on time. It serves as an independent variable to predict the dependent variable in time.
Descriptive model
A descriptive model differentiates the patterns and relationships in data. A descriptive model does not attempt to generalize to a statistical population or random process. A predictive model attempts to generalize to a population or random process. Predictive models should give prediction intervals and must be cross-validated; that is, they must prove that they can be used to make predictions with data that was not used in constructing the model.
Descriptive analytics focuses on the summarization and conversion of the data into useful information for reporting and monitoring.
Clustering:
Clustering is grouping a set of objects so that objects in the same group called a cluster are more similar than those in other groups clusters.
Association rules:
Association rules determine a causal relationship between huge sets of data objects. The way the algorithm works is that you have. For example, a list of items you purchase at the grocery store for the past six months data, and it calculates a percentage at which items are purchased together. For example, what are the chances of you buying milk with cereal?
Sequence:
Sequence refers to the discovery of useful patterns in the data is in relation to some objective of how it is interesting.
Summarization:
Summarization holds a data set in more depth which is easy to understand form.