SciPy Cluster
Clustering is the procedure of dividing the datasets into groups consisting of similar data-points. For example, the Items are arranged in the shopping mall. Data Points are in the same group must be identical as possible and should be different from the other groups. There are two types of the cluster, which are:
- Central
- Hierarchy
The k- means clustering algorithm is a simple unsupervised algorithm that is used to predict groupings from within an unlabeled dataset. The prediction is based on the number of cluster centers present(k) and the nearest mean value (measured in Euclidian distance between observations).
K-means Algorithm
The steps are as follows, suppose we have an input x1,x2, x3,….xn, data and value K.
Step – 1:
Select K random points as a cluster center called centroid. Suppose these are c1,c2,…ck, and it can be written as follows:
c1,c2,...ck
C is the set of all centroid.
Step-2:
Assign each input value xi to the nearest center by calculating its Euclidean (L2) distance between the point and each centroid.
Step-3:
In this step, we get the new centroid by calculating the average of all the points assigned to the cluster.
Step-4:
We repeat steps 2 and 3 until none of the clusters remains unstable.
K-means cluster and vector quantization (scipy.cluster.vq)
SciPy provides functions for K-means clustering, generating codebooks from k-means models, and quantizing vector by comparing them with centroid in a codebook.
| Function | Description |
|---|---|
| scipy.cluster.vq.whiten(obs, check_finite=True ) | It normalizes a group of observation on features. |
| scipy.cluster.vq.vq(obs, code_book,check_finite=True) | It assigns codes from a codebook to observation. |
| scipy.cluster.vq.kmeans(obs, k_or_guess, iter=20, thresh=1e-05, check_finite=True) | It performs k-means on a set of observation vectors forming k clusters. |
| scipy.cluster.vq.kmeans2(data,k,iter=10, thresh=1e-05, minit=’random’, missing=’warn’, check_finite=True) | It classifies a set of observations into k clusters using the k-means algorithm. |
K-Means Implementation in SciPy
Here, we will understand the implementation of K- means in SciPy
Import K-means
The following statement is used to implement the K-means algorithm:
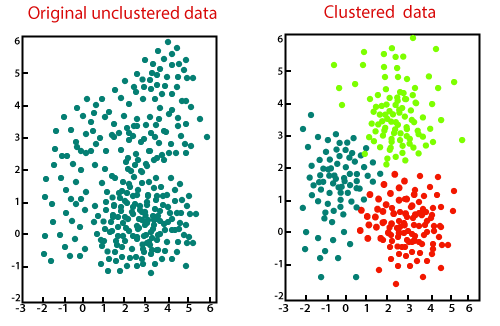
Computing K-means with three Clusters
The K-means algorithm iterates again and again and adjusts the centroid until necessary progress cannot made change in distortion, since the last iteration is less than some threshold. Consider the following example:
Output:
[[1.97955982 1.78985952 1.51775359] [2.6926236 2.70116313 2.75279787] [0.84636826 0.93081751 1.0708057 ]]