Working of RNN in TensorFlow
Recurrent Neural Networks have vast applications in image classification and video recognition, machine translation, and music composition.
Consider an image classification use-case where we have trained the neural network to classify images of some animals.
So, let’s feed an image of a cat or a dog; the network provides an output with the corresponding label to the picture of a cat or a dog.
See the below diagram:
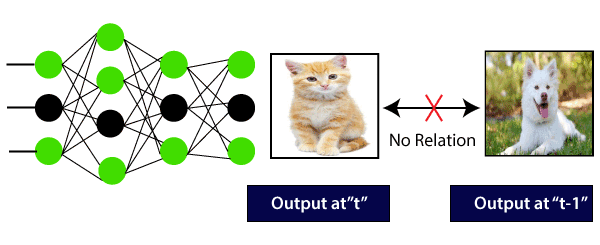
Here, the first output being a cat will not influence the previous output, which is a dog. This means that output at a time ‘t’ is autonomous of output at the time ‘t-1?.
Consider the scenario where we will require the use of the last obtained output:
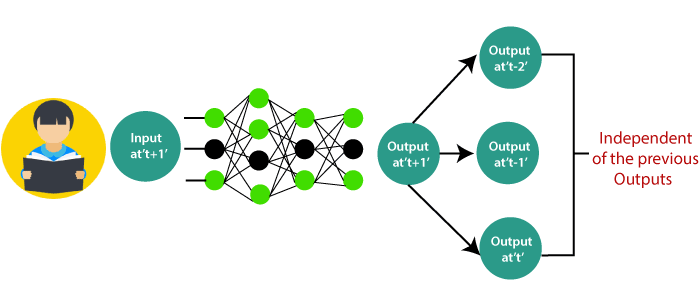
The concept is the same as reading a book. With every page we move forward into, we need the understanding of previous pages to make complete sense of the information in most of the cases.
With the help of the feed-forward network, the new output at the time ‘t+1? has no relation with outputs at either time t, t-1, t-2.
So, the feed-forward network cannot be used when predicting a word in a sentence as it will have no absolute relation with the previous set of words.
But, with the help of Recurrent Neural Networks, this challenge can be overcome.
See the following diagram:
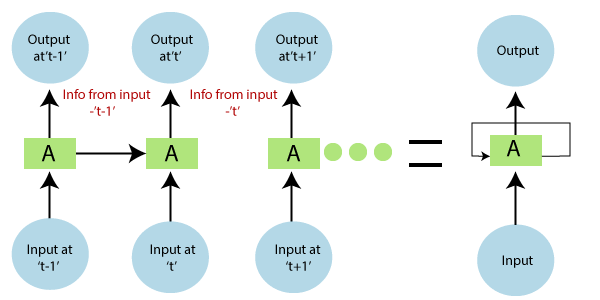
In the above diagram, we have specific inputs at-1? which is fed into the network. These inputs will lead to parallel outputs at time ‘t-1’ as well.
In the next timestamp, information from the previous input’t-1? is provided along with input at’t? to provide the output at ‘t eventually.’
This process repeats itself, to ensure that the latest inputs are aware and can use the information from the previous timestamp is obtained.
The recurrent network is a type of artificial neural network which is designed to recognize patterns in sequences of data. Like, text, genomes, handwriting, the spoken word, numerical times series data from sensors, stock markets, and government agencies.
For better understanding, consider the following comparison:
We go to the gym regularly, and the trainer has given us the schedule of our workout:

Note that all the exercises are repeated in a proper order every week. Let us use a feed-forward network to trying and predicting the types of exercises.
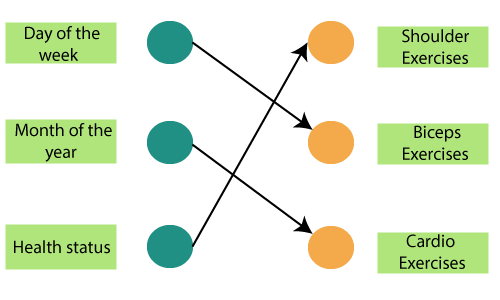
The inputs are the day, month, and health status. A neural network has been trained using these inputs to provide the prediction of the exercise.
However, this will not very accurate, considering the input. To fix this, we make use of the concept of Recurrent Neural Networks, as shown below:
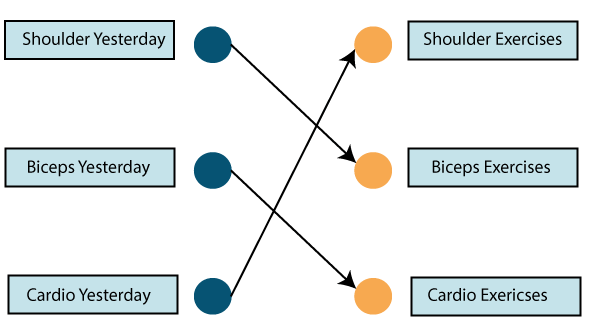
In this case, find the inputs to be workout done on the previous day.
So if we did a shoulder exercise yesterday, we could do a bicep exercise today, and this goes on for the rest of the week.
However, if we happen to miss a day at the gym, the data from the previously attended timestamp can be considered below.
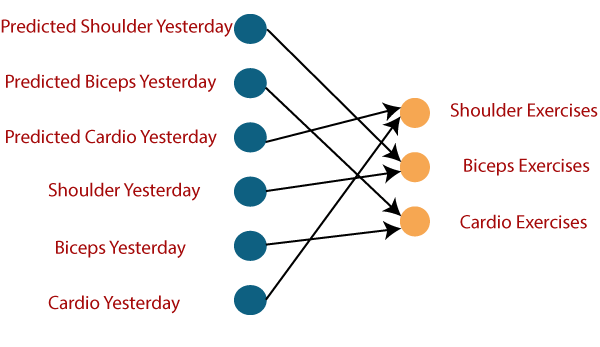
If a model is experienced based on the data it obtains from the last exercises, the output from the model will be accurate.
To sum it, let us convert the data into vectors.
Where vectors are numbers which are input to the model to denote if we have done the exercise or not.
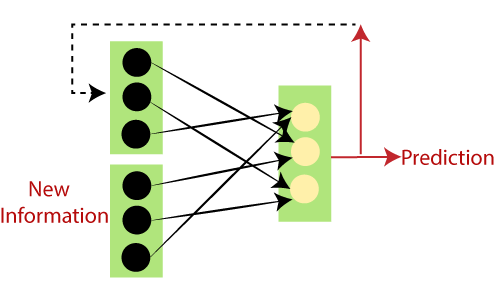
So, if we have a shoulder exercise, the corresponding node will be ‘1’, and the rest of the exercise nodes will be mapped to ‘0’.
We have to check the math behind the working of the neural network.
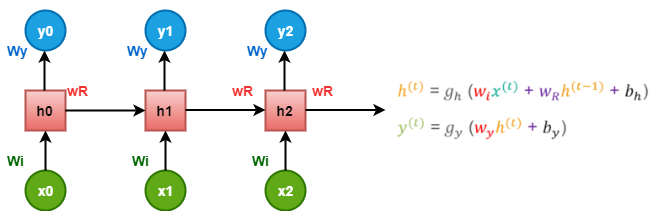
examine ‘w’ to be the weight matrix and ‘b’ as the bias:
At time t=0, the input is ‘x0, and the task is to figure out what is ‘h0’. Substituting t=0 in the equation and acquiring the function h(t) value. The next value of ‘y0’ is finding out using the previously calculated values when applied to the new formula.
The same process is repeated through all of the timestamps in the model to train a model.
Training Recurrent Neural Networks
Recurrent Neural Networks use a backpropagation algorithm for training, but it is applied for each timestamp. It is commonly known as Back-propagation by Time (BTT).
Some issues with Back-propagation, such as:
- Vanishing Gradient
- Exploding Gradient
Vanishing Gradient
In Vanishing Gradient’s use of backpropagation, the goal is to calculate the error, which is found out by finding out the difference between the actual found out by finding out the difference between the actual output and the model output and raising that to a power of 2.
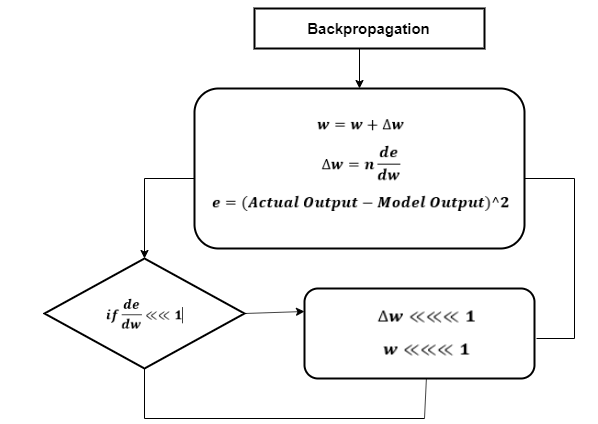
With the calculated error, the changes in the mistake concerning the difference in the weight are estimated. But with each learning rate, this can multiply with the same model.
So, Product of the learning rate with the change pass to the value, which is a definite change in weight.
The change in weight is added to the old set of weights for every training iteration, as shown in the below figure. The assign here is when the change in weight is multiplied, and then the value is less.
Exploding Gradient
The working of the collapse gradient is similar, but the weights here change extremely instead of negligible change. Notice the small here:
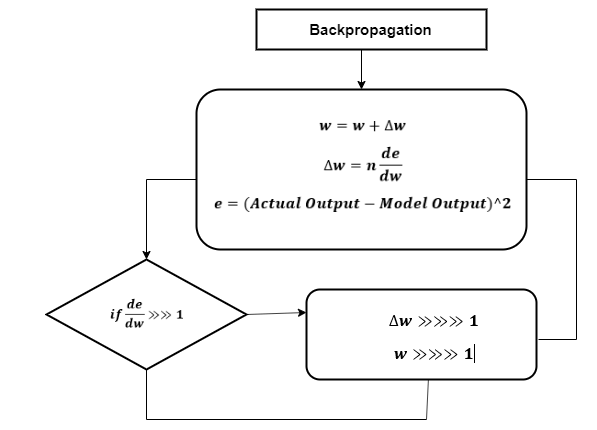
We have to overcome both of these, and it is some challenge at first.
| Exploding gradients | Vanishing gradients |
|---|---|
|
|
|
|
|
|
What are long-term dependencies?
Many times only recent data is desired in a model to performing the operations. But there may be a requirement from a piece of information which was obtained in the past.