Data Warehouse Process Architecture
The process architecture defines an architecture in which the data from the data warehouse is processed for a particular computation.
Following are the two fundamental process architectures:
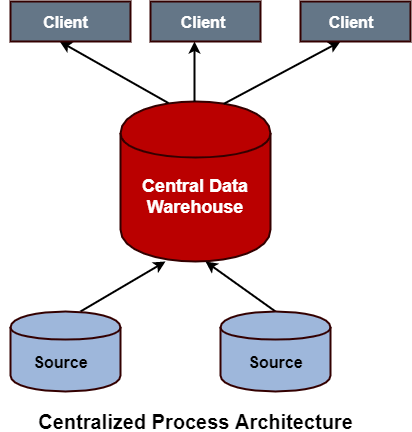
Centralized Process Architecture
In this architecture, the data is collected into single centralized storage and processed upon completion by a single machine with a huge structure in terms of memory, processor, and storage.
Centralized process architecture evolved with transaction processing and is well suited for small organizations with one location of service.
It requires minimal resources both from people and system perspectives.
It is very successful when the collection and consumption of data occur at the same location.
Distributed Process Architecture
In this architecture, information and its processing are allocated across data centers, and its processing is distributed across data centers, and processing of data is localized with the group of the results into centralized storage. Distributed architectures are used to overcome the limitations of the centralized process architectures where all the information needs to be collected to one central location, and results are available in one central location.
There are several architectures of the distributed process:
Client-Server
In this architecture, the user does all the information collecting and presentation, while the server does the processing and management of data.
Three-tier Architecture
With client-server architecture, the client machines need to be connected to a server machine, thus mandating finite states and introducing latencies and overhead in terms of record to be carried between clients and servers.
N-tier Architecture
The n-tier or multi-tier architecture is where clients, middleware, applications, and servers are isolated into tiers.
Cluster Architecture
In this architecture, machines that are connected in network architecture (software or hardware) to approximately work together to process information or compute requirements in parallel. Each device in a cluster is associated with a function that is processed locally, and the result sets are collected to a master server that returns it to the user.
Peer-to-Peer Architecture
This is a type of architecture where there are no dedicated servers and clients. Instead, all the processing responsibilities are allocated among all machines, called peers. Each machine can perform the function of a client or server or just process data.