Types of Database Parallelism
Parallelism is used to support speedup, where queries are executed faster because more resources, such as processors and disks, are provided. Parallelism is also used to provide scale-up, where increasing workloads are managed without increase response-time, via an increase in the degree of parallelism.
Different architectures for parallel database systems are shared-memory, shared-disk, shared-nothing, and hierarchical structures.
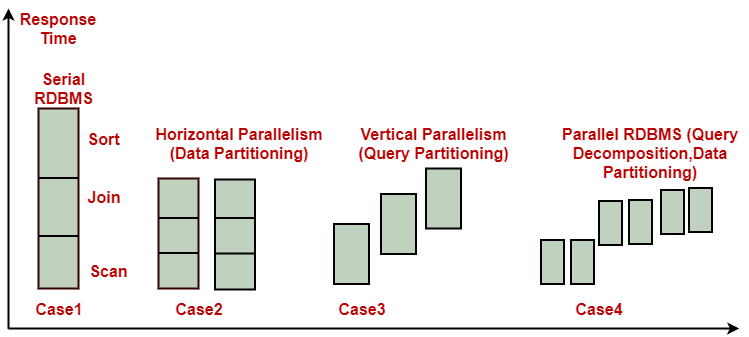
(a)Horizontal Parallelism: It means that the database is partitioned across multiple disks, and parallel processing occurs within a specific task (i.e., table scan) that is performed concurrently on different processors against different sets of data.
(b)Vertical Parallelism: It occurs among various tasks. All component query operations (i.e., scan, join, and sort) are executed in parallel in a pipelined fashion. In other words, an output from one function (e.g., join) as soon as records become available.
Intraquery Parallelism
Intraquery parallelism defines the execution of a single query in parallel on multiple processors and disks. Using intraquery parallelism is essential for speeding up long-running queries.
Interquery parallelism does not help in this function since each query is run sequentially.
To improve the situation, many DBMS vendors developed versions of their products that utilized intraquery parallelism.
This application of parallelism decomposes the serial SQL, query into lower-level operations such as scan, join, sort, and aggregation.
These lower-level operations are executed concurrently, in parallel.
Interquery Parallelism
In interquery parallelism, different queries or transaction execute in parallel with one another.
This form of parallelism can increase transactions throughput. The response times of individual transactions are not faster than they would be if the transactions were run in isolation.
Thus, the primary use of interquery parallelism is to scale up a transaction processing system to support a more significant number of transactions per second.
Database vendors started to take advantage of parallel hardware architectures by implementing multiserver and multithreaded systems designed to handle a large number of client requests efficiently.
This approach naturally resulted in interquery parallelism, in which different server threads (or processes) handle multiple requests at the same time.
Interquery parallelism has been successfully implemented on SMP systems, where it increased the throughput and allowed the support of more concurrent users.
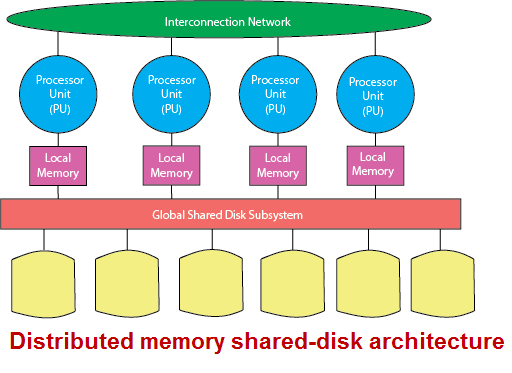
Shared Disk Architecture
Shared-disk architecture implements a concept of shared ownership of the entire database between RDBMS servers, each of which is running on a node of a distributed memory system.
Each RDBMS server can read, write, update, and delete information from the same shared database, which would need the system to implement a form of a distributed lock manager (DLM).
DLM components can be found in hardware, the operating system, and separate software layer, all depending on the system vendor.
On the positive side, shared-disk architectures can reduce performance bottlenecks resulting from data skew (uneven distribution of data), and can significantly increase system availability.
The shared-disk distributed memory design eliminates the memory access bottleneck typically of large SMP systems and helps reduce DBMS dependency on data partitioning.
Shared-Memory Architecture
Shared-memory or shared-everything style is the traditional approach of implementing an RDBMS on SMP hardware.
It is relatively simple to implement and has been very successful up to the point where it runs into the scalability limitations of the shared-everything architecture.
The key point of this technique is that a single RDBMS server can probably apply all processors, access all memory, and access the entire database, thus providing the client with a consistent single system image.
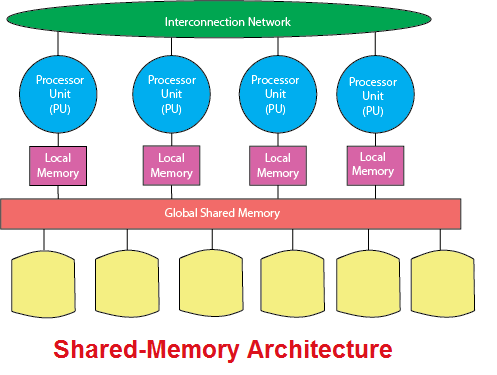
In shared-memory SMP systems, the DBMS considers that the multiple database components executing SQL statements communicate with each other by exchanging messages and information via the shared memory.
All processors have access to all data, which is partitioned across local disks.
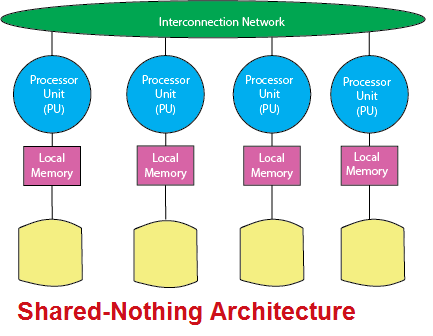
Shared-Nothing Architecture
In a shared-nothing distributed memory environment, the data is partitioned across all disks, and the DBMS is “partitioned” across multiple co-servers, each of which resides on individual nodes of the parallel system and has an ownership of its disk and thus its database partition.
A shared-nothing RDBMS parallelizes the execution of a SQL query across multiple processing nodes.
Each processor has its memory and disk and communicates with other processors by exchanging messages and data over the interconnection network.
This architecture is optimized specifically for the MPP and cluster systems.
The shared-nothing architectures offer near-linear scalability. The number of processor nodes is limited only by the hardware platform limitations (and budgetary constraints), and each node itself can be a powerful SMP system.