
A measure of central tendency is a single value that represents the center point of a dataset. This value can also be referred to as “the central location” of a dataset.
In statistics, there are three common measures of central tendency:
- The mean
- The median
- The mode
Each of these measures finds the central location of a dataset using different methods. Depending on the type of data you’re analyzing, one of these three measures may be better to use than the other two.
In this post, we’ll take a look at how to calculate each of the three measures of central tendency along with how to determine which measure is best to use based on your data.
Why Are Measures of Central Tendency Useful?
Before we look at how to calculate the mean, median, and mode, it’s helpful to first understand why these measures are actually helpful in the first place.
Consider the following scenario:
A young couple is trying to decide where to buy their first home in a new city and the most they can spend is $150,000. Some neighborhoods in the city have expensive houses, some have cheap houses, and others have medium-priced houses. They want to easily narrow down their search to specific neighborhoods that are within their budget.
If the couple just looked at the individual home prices in each neighborhood, they might have a tough time determining which neighborhoods best fit their budget because they might see something like this:
Neighborhood A home prices: $140k, $190k, $265k, $115k, $270k, $240k, $250k, $180k, $160k, $200k, $240k, $280k, …
Neighborhood B home prices: $140k, $290k, $155k, $165k, $280k, $220k, $155k, $185k, $160k, $200k, $190k, $140k, $145k, …
Neighborhood C home prices: $140k, $130k, $165k, $115k, $170k, $100k, $150k, $180k, $190k, $120k, $110k, $130k, $120k, …
However, if they knew the average (e.g. a measure of central tendecy) home price in each neighborhood, then they could narrow down their search much quicker because they could more easily identify which neighborhood has home prices that are within their budget:
Average Neighborhood A home price: $220k
Average Neighborhood B home price: $190k
Average Neighborhood C home price: $140k
By knowing the average home price in each neighborhood, they can quickly see that Neighborhood C is likely to have the most homes available within their budget.
This is the benefit of using a measure of central tendency: It helps you understand the central value of a dataset, which tends to describe where the data values typically fall. In this particular example, it helps the young couple understand the typical home price in each neighborhood.
Takeaway: A measure of central tendency is useful because it provides us with a single value that describes the “center” of a dataset. This helps us understand a dataset much more quickly compared to simply looking at all of the individual values in the dataset.
Mean
The most commonly used measure of central tendency is the mean. To calculate the mean of a dataset, you simply add up all of the individual values and divide by the total number of values.
Mean = (sum of all values) / (total # of values)
For example, suppose we have the following dataset that shows the number of home runs hit by 10 baseball players on the same team in one season:
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 15 | 22 | 21 | 12 | 9 | 11 | 27 | 14 | 13 |
The mean number of home runs hit per player can be calculated as:
Mean = (8+15+22+21+12+9+11+27+14+13) / 10 = 15.2 home runs.
Median
The median is the middle value in a dataset. You can find the median by arranging all the individual values in a dataset from smallest to largest and finding the middle value. If there are an odd number of values, the median is the middle value. If there are an even number of values, the median is the average of the two middle values.
For example, to find the median number of home runs hit by the 10 baseball players in the previous example we can arrange the players in order from least to greatest number of home runs hit:
| Player | #1 | #6 | #7 | #5 | #10 | #9 | #2 | #4 | #3 | #8 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 9 | 11 | 12 | 13 | 14 | 15 | 21 | 22 | 27 |
Since we have an even number of values, the median is simply the average of the two middle values: 13.5.
Instead, consider if we had nine players:
| Player | #1 | #6 | #7 | #5 | #9 | #2 | #4 | #3 | #8 |
|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 9 | 11 | 12 | 14 | 15 | 21 | 22 | 27 |
In this case, since we have an odd number of values the median is simply the middle value: 14.
The Mode
The mode is the value that occurs most often in a dataset. A dataset can have no mode (if no value repeats), one mode, or multiple modes.
For example, the following dataset has no mode:
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 9 | 11 | 12 | 13 | 14 | 15 | 21 | 22 | 27 |
The following dataset has one mode: 15. This is the value that occurs most frequently.
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 9 | 11 | 12 | 13 | 15 | 15 | 21 | 22 | 27 |
The following dataset has three modes: 8, 15, 19. These are the values that occur most frequently.
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 8 | 11 | 12 | 15 | 15 | 17 | 19 | 19 | 27 |
The mode can be a particularly helpful measure of central tendency when working with categorical data because it tells us which category occurs most frequently. For example, consider the following bar chart that shows the results of a survey about people’s favorite color:
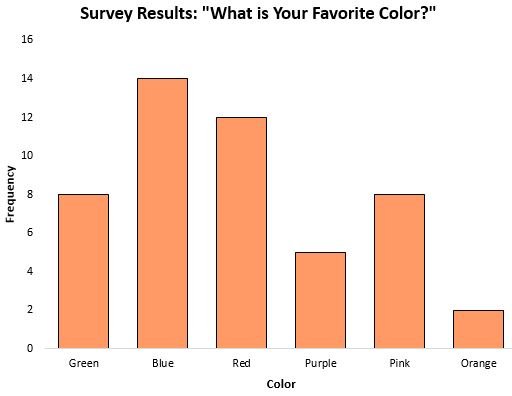
The mode, or the response that occurred most frequently, was blue.
In scenarios where the data is categorical (like the one above), it’s not even possible to calculate the median or the mean, so the mode is the only measure of central tendency we can use.
The mode can also be used for numerical data, like we saw in the above example with baseball players. However, the mode tends to be less helpful at answering the question “What’s a typical value for this dataset?”
For example, suppose we want to know the typical number of home runs hit by a baseball player on this team:
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 8 | 8 | 11 | 12 | 15 | 15 | 17 | 19 | 19 | 27 |
The mode of this dataset is 8, 15, and 19, since these are the values that occur most frequently. However, these aren’t terribly helpful for understanding the typical number of home runs hit by a player on the team. A better measure of central tendency would be the median (15) or the mean (also 15) in this case.
The mode is also a poor measure of central tendency when it happens to be a number that is far away from the rest of the values. For example, the mode of the following dataset is 30, but this doesn’t actually represent the “typical” number of home runs hit per player on the team:
| Player | #1 | #2 | #3 | #4 | #5 | #6 | #7 | #8 | #9 | #10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Home Runs | 5 | 6 | 7 | 10 | 11 | 12 | 13 | 15 | 30 | 30 |
Once again, the mean or median would do a better job of describing the center location of this dataset.
When to Use the Mean, Median, and Mode
We’ve seen that the mean, median, and mode all measure the central location, or the “typical value,” of a dataset in very different ways:
Mean: Finds the average value in a dataset.
Median: Finds the middle value in a dataset.
Mode: Finds the most frequently occurring value in a dataset.
Here are the scenarios where certain measures of central tendency are better to use than others:
When to use the mean
It is best to use the mean when the distribution of the data is fairly symmetrical and there are no outliers.
For example, suppose we have the following distribution that shows the salaries of individuals in a certain town:
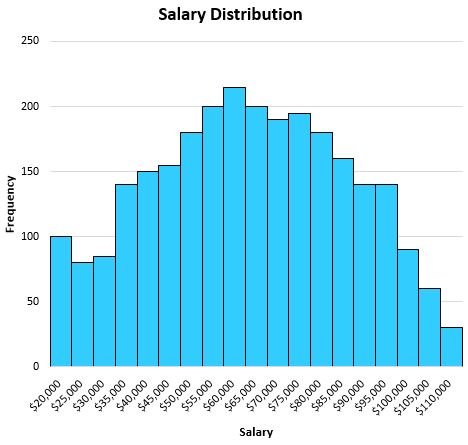
Since this distribution is fairly symmetrical (i.e. if you split it down the middle, each half would look roughly equal) and there are no outliers (i.e. no extremely high salaries), the mean will do a good job of describing this dataset.
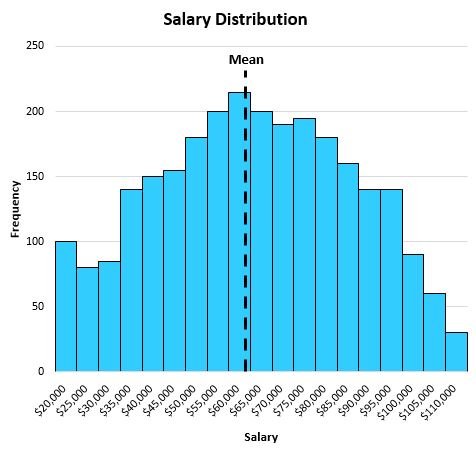
The mean turns out to be $63,000, which is roughly located in the center of the distribution:
When to use the median
It is best to use the median when the distribution of the data is either skewed or there are outliers present.
Skewed data:
When the distribution is skewed, the median still does a good job of capturing the center location. For example, consider the following distribution of salaries for individuals in a certain town:
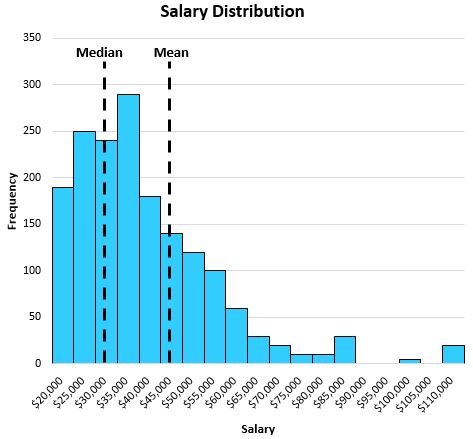
The median does a better job of capturing the “typical” salary of an individual than the mean. This is because the large values on the tail end of a distribution tend to pull the mean away from the center and towards the long tail.
In this particular example, the mean tells us that the typical individual earns about $47,000 per year in this town while the median tells us that the typical individual only earns about $32,000 per year, which is much more representative of the typical individual.
Outliers:
The median also does a better job of capturing the central location of a distribution when there are outliers present in the data. For example, consider the following chart that shows the square footage of houses on a certain street:
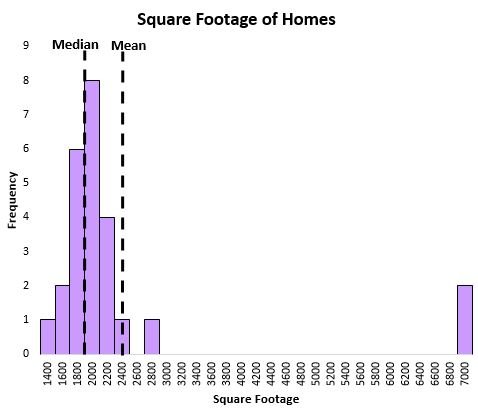
The mean is heavily influenced by a couple extremely large houses, while the median is not. Thus, the median does a better job of capturing the “typical” square footage of a house on this street compared to the mean.
When to use the mode
It is best to use the mode when you are working with categorical data and you want to know which category occurs most frequently. Here are a couple examples:
- You conduct a survey about people’s favorite colors and you want to know which color occurs most frequently in the responses.
- You conduct a survey about people’s preferences among three choices for a website design and you want to know which design people prefer most.
As mentioned earlier, if you’re working with categorical data then it’s not even possible to calculate the median or mean, which leaves the mode as the only measure of central tendency.
In general, if you’re working with numerical data like square footage of homes, number of home runs hit per player, salary per individual, etc. then it’s usually better to use the median or the mean to describe the “typical” value in the dataset.
Note: It’s important to note that if a dataset is perfectly normally distributed, then the mean, median, and mode are all the same value.