Mini Batch K-means clustering algorithm
K-means is among the most well-known clustering algorithms due to its speed performance. With the increase in the volume of data being analysed and the computational time of K-means grows due to its limitation of storing the entire dataset to be stored in memory. This is why a variety of approaches have been proposed to decrease the temporal and spatial costs of the method. Another method that can be used is the Mini Batch K-means algorithm.
The main idea of Mini Batch K-means algorithm is to utilize small random samples of fixed in size data, which allows them to be saved in memory. Every time a new random sample of the dataset is taken and used to update clusters; the process is repeated until convergence. Each mini-batch updates the clusters with an approximate combination of the prototypes and the data results, using the learning rate, which reduces with the number of iterations. This rate of learning is the reverse of the number of data assigned to the cluster as it goes through the process. When the number of repetitions increases and the impact of adding new data decreases, convergence is observed when no changes to the clusters happen in consecutive iterations. The research suggests that the algorithm could result in significant savings in computational time but at the cost of a decrease in the quality of the clusters, but not an extensive analysis of the method has yet been conducted to determine how the specific characteristics of the data like the size of the clusters, or its size, impact the quality of the partition.
Each batch of data is assigned to clusters based on the prior locations of the cluster’s centroids. The algorithm uses small, random portions of the data each time. Then, it updates the positions of the cluster’s centroids based on the updated points from the batch. The update is one of gradient descent updates that is much quicker than a standard batch K-Means update.
The following is an algorithm used for the Mini K-means batch.

Python implementation of the above algorithm using scikit-learn library:
Code:
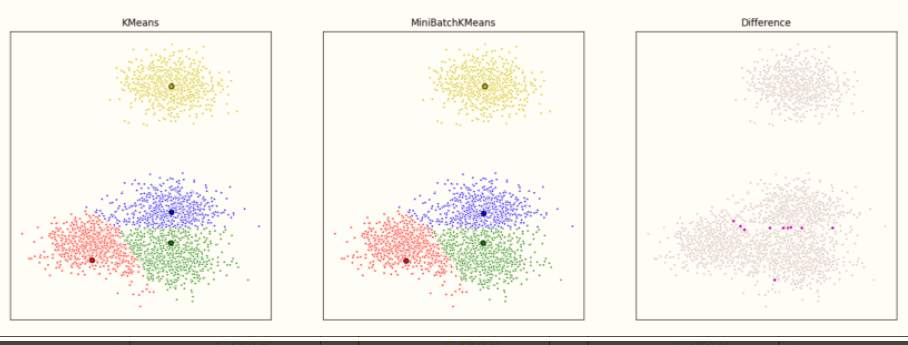
A mini-batch K-means is quicker but produces somewhat different outcomes than usual batch K-means.
In this case, we group a set of data first using K-means, then using mini-batch K-means. We then display the results. We also plot points with different labels in these two methods.
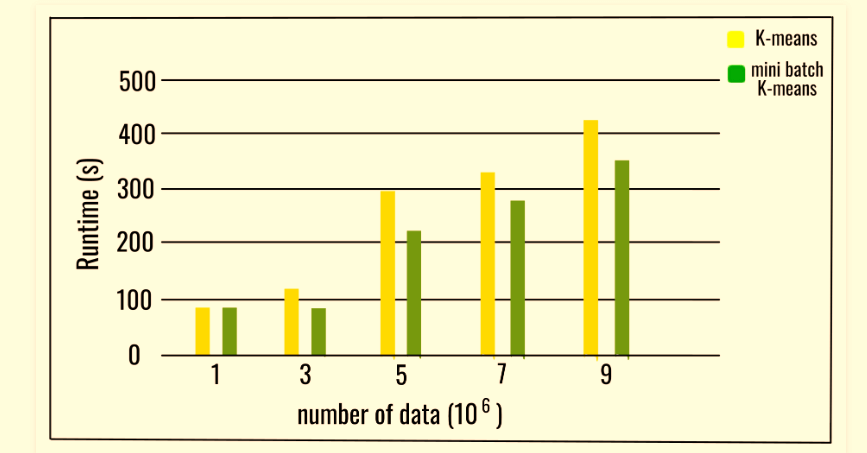
As the number of clusters and the amount of data grows, computation time also rises. The time savings in computation is evident only at times when the number of clusters is massive. The impact of the size of the batch on the time to compute is more apparent when the number of clusters is higher. It is possible to conclude that the increase in the number of clusters reduces the degree of similarity between the Mini-Batch K-Means algorithm with the solution K-means. At the same time, the agreement between partitions decreases when the number of clusters increases. However, the objective function does not diminish in the same way. This means that all final partitions will differ; however, they are closer in quality.