Linux uniq Command
Linux uniq command is used to remove all the repeated lines from a file. Also, it can be used to display a count of any word, only repeated lines, ignore characters, and compare specific fields. It is one of the most frequently used commands in the Linux system. It is often used with the sort command because it compares adjacent characters. It discards all the identical lines and writes the output.
Syntax:
Options:
Some useful command line options of the uniq command are as following:
-c, –count: it prefixes the lines by the number of occurrences.
-d, –repeated: it is used to print duplicate lines, one for each group.
-D: It is used to print all the duplicate lines.
–all-repeated[=METHOD]: It is quite similar to the ‘-D’ option, the difference between both the options is that it allows separation of groups with an empty line.
-f, –skip-fields=N: It is used to avoid comparison of the first N fields.
–group[=METHOD]: It is used to display all items and separates the groups with an empty line.
-i, –ignore-case: It is used to ignore the differences while comparing.
-s, –skip-chars=N: It is used to avoid the comparison of the first N characters.
-u, –unique: it is used to print unique lines.
-z, –zero-terminated: It is used for the line delimiter is NUL and not newline mode.
-w, –check-chars=N: It is used to compare not more than N characters in lines.
–help: It is used to display help documentation.
–version: It is used to display the version information.
Examples of uniq Command
Let’s see the following examples of the uniq command:
- Remove repeated lines
- count the number of occurrences of a word
- Display the repeated lines
- Display the unique lines
- Ignore characters in comparison
- Ignore fields in comparison
Remove repeated lines
To remove repeated lines from a file, execute the basic uniq command as follows:
The above command will remove the duplicate lines from the file ‘dupli.txt.’ Consider the below output:
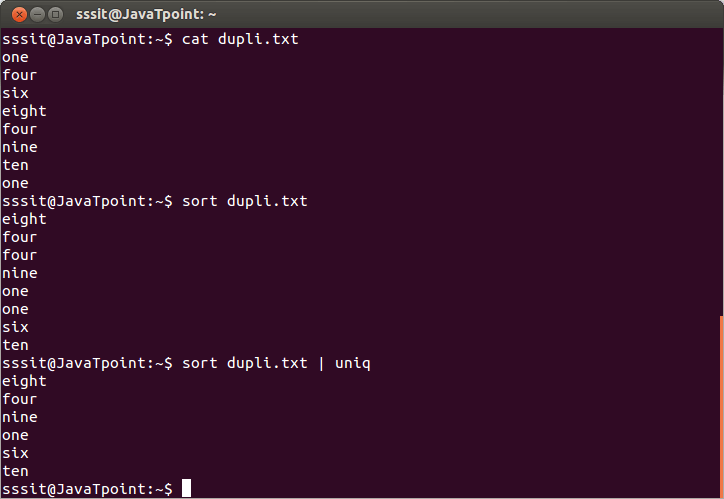
From the above output, the repeating words are ignored.
Count the number of occurrences of a word
We can count the number of occurrences of a word by using the uniq command. The ‘-c’ option is used to count the word. Execute it as follows:
The above command will count the words which come in ‘dupli.txt’. Consider the below output:
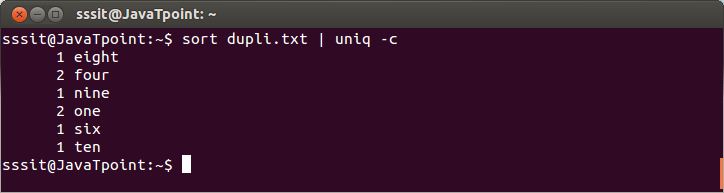
From the above output, the command “sort dupli.txt | uniq -c” counts the number of times a word is repeating.
Display the repeated lines
The ‘-d’ option is used to display only the repeated lines. It will only display the lines that will be more than once in a file and write the output to standard output. Consider the below command:
The above command will display only the repeated lines. Consider the below output:

Display the unique lines
The ‘-u’ option is used to display only the unique lines ( which are not repeated). It will only display the lines that occur only once and write the result to standard output. Consider the below command:
The above command will display only the unique lines from the file ‘dupli.txt’. Consider the below output:

Ignore characters in comparison
The ‘-s’ option is used to ignore the characters in comparison. It will ignore the specified number of characters and display the result to standard output. Consider the below command:
The above command will ignore the first two characters in comparison from the file ‘dupli.txt’. Consider the below output:

Ignore fields in comparison
The ‘-f’ option is used to ignore the fields. Consider the below command:
The above command will not compare the first two fields from the file ‘dupli2.txt’. Consider the below output:

From the above output, the first two fields are skipped, and the rest of all fields are compared from the file ‘dupli2.txt’.