Working of Style Transferring
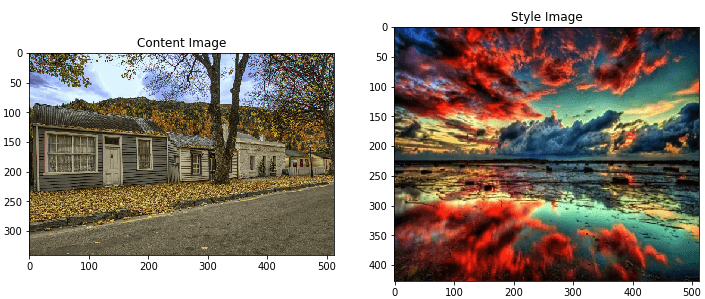
Neural style transfer is the optimization technique used to take two images- a content image and a style reference image and blend them, so the output image looks like the content image, but it “painted” in the style of the style reference image.
Import and configure the modules
Open Google colab
Output:
TensorFlow 2.x selected.
Output:
Downloading data from https://www.eadegallery.co.nz/wp-content/uploads/2019/03/626a6823-af82-432a-8d3d-d8295b1a9aed-l.jpg 1122304/1117520 [==============================] - 1s 1us/step Downloading data from https://i.pinimg.com/originals/11/91/4f/11914f29c6d3e9828cc5f5c2fd64cfdc.jpg 49152/43511 [=================================] - 0s 0us/step5. def
Check the greatest measurement to 512 pixels.
Creating a function to show the image
Output:
Output:
Downloading data from https://github.com/fchollet/deep-learning- models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 8s 0us/step TensorShape([1, 1000])
Output:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 40960/35363 [==================================] - 0s 0us/step [('mobile_home', 0.7314594), ('picket_fence', 0.119986326), ('greenhouse', 0.026051044), ('thatch', 0.023595566), ('boathouse', 0.014751049)] Define style and content representations
Use the middle layers of the model to the content and style representation of the image. Starting from the input layer, the first few layer activation represent low-level represent like edges and textures.
For the input image, try to match the similar style and content target representation at the intermediate layers.
Load the VGG19 and run it on our image to ensure it used correctly here.
Output:
Download data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Intermediate layers for style and content
At the high level, to a network to perform image classification, it understands the image and requires taking the image as the pixels and building an internal illustration that converts the raw image pixels into a complex features present within the image.
This is also a reason why the convolutional neural networks can generalize well: they can capture the deviating and defining features within classes (e.g., cats vs. dogs) that are agnostic where the image is fed into the model and output arrangement label, the model deliver as a complex feature extractor. By accessing intermediate layers of the model, we’re able to describe the style and content of input images.
Build the model
The network in tf.keras.applications are defined, so we can easily extract the intermediate layer values using the Keras functional API.
To define any model using the functional API, specify the inputs and outputs:
model= Model(inputs, outputs)
The given function builds a VGG19 model that returns a list of intermediate layer.
Output:
block1_conv1 shape: (1, 427, 512, 64) min: 0.0 max: 763.51953 mean: 25.987665 block2_conv1 shape: (1, 213, 256, 128) min: 0.0 max: 3484.3037 mean: 134.27835 block3_conv1 shape: (1, 106, 128, 256) min: 0.0 max: 7291.078 mean: 143.77878 block4_conv1 shape: (1, 53, 64, 512) min: 0.0 max: 13492.799 mean: 530.00244 block5_conv1 shape: (1, 26, 32, 512) min: 0.0 max: 2881.529 mean: 40.596397
Gram matrix:
Calculating style
The content of the image is represented by the values of the common features of the map.
Calculate a Gram Matrix, which includes this information by taking the output product over all locations.
The Gram matrix can be calculated for a particular layer as:
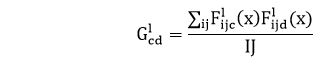
This is implemented concisely using the tf.linalg.einsum function:
Extracting the style and content of image
Building the model that returns the content and style tensor.
When called on the image, this model returns the gram matrix (style) of the style_layers and content of the content_layers:
Output:
Styles: block1_conv1 shape: (1, 64, 64) min: 0.0055228453 max: 28014.557 mean: 263.79025 block2_conv1 shape: (1, 128, 128) min: 0.0 max: 61479.496 mean: 9100.949 block3_conv1 shape: (1, 256, 256) min: 0.0 max: 545623.44 mean: 7660.976 block4_conv1 shape: (1, 512, 512) min: 0.0 max: 4320502.0 mean: 134288.84 block5_conv1 shape: (1, 512, 512) min: 0.0 max: 110005.37 mean: 1487.0381 Contents: block5_conv2 shape: (1, 26, 32, 512) min: 0.0 max: 2410.8796 mean: 13.764149
Run gradient descent
With this style and content extractor, we implement the style transfer algorithm. Do this by evaluating the mean square error in our image’s output relative to each target, then take the weighted sum of the losses.
Set our style and content target values:
Define a tf.Variable to contain the image to hold. Initialize it with the help of content image (the tf.Variable be the same shape as the content image):
This is a floating image, define a function to keep the pixel value between 0 and 1:
Create the optimizer. The paper recommends LBFGS:
To optimizing it, use a weight combination of the two losses to get the total loss:
Use the function tf.GradientTape to update the image.
Run below steps to test:
Output:

Transforming the image
Performing a longer optimization in this step:
Output:



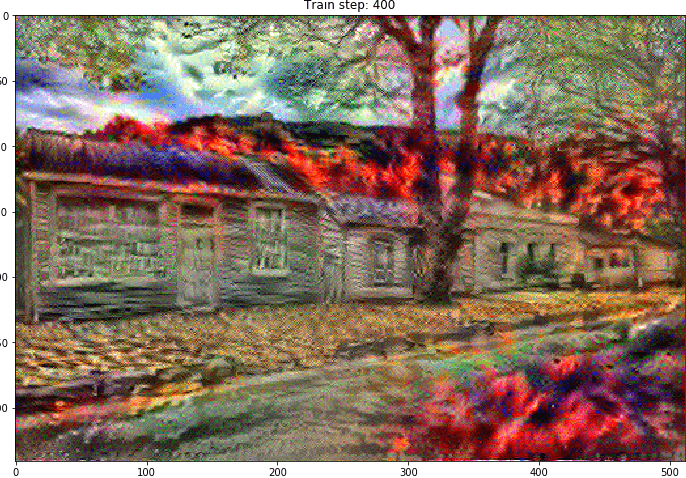





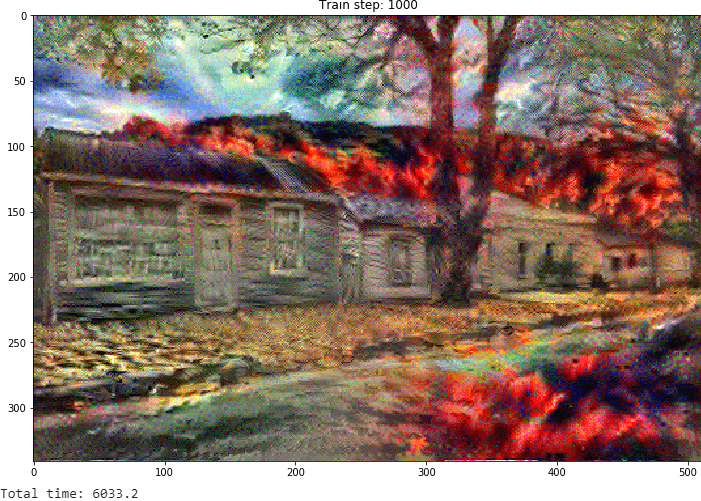
Total variation loss
Output:
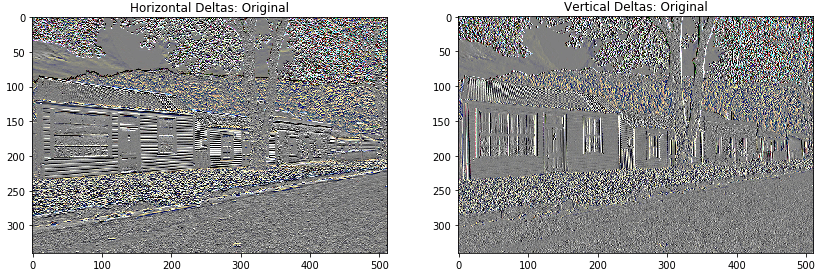
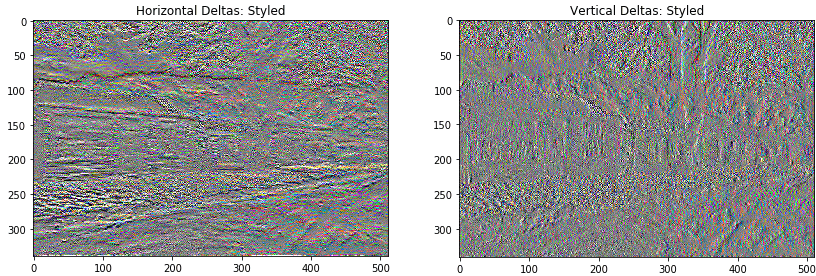
This shows how the high frequency component have increased.
This high frequency component is an edge-detector. We get same output from the edge detector, from the given example:
Output:
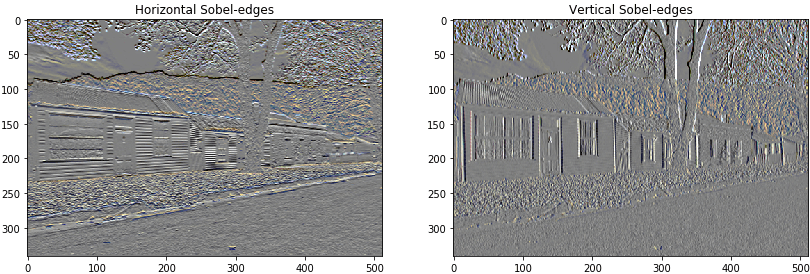
The regularization loss associated with this is sum of the square of the value:
Output:
99172.59
That demonstrate what it does. But there’s no need to implement it ourselves, it includes a standard implementation:
Output:
array([99172.59], dtype=float32)
Re-running the optimization function
Pick the weight for the function total_variation_loss:
Now, train_step function:
Reinitializing the optimization variable:
And run the optimization:
Output:

finally save the result: