86
Spark groupByKey Function
In Spark, the groupByKey function is a frequently used transformation operation that performs shuffling of data. It receives key-value pairs (K, V) as an input, group the values based on key and generates a dataset of (K, Iterable) pairs as an output.
Example of groupByKey Function
In this example, we group the values based on the key.
- To open the Spark in Scala mode, follow the below command.
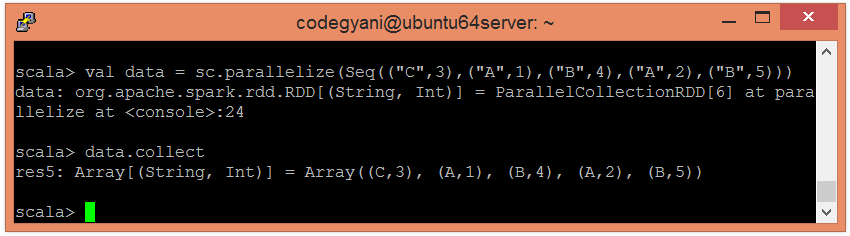
- Create an RDD using the parallelized collection.
Now, we can read the generated result by using the following command.
- Apply groupByKey() function to group the values.
- Now, we can read the generated result by using the following command.
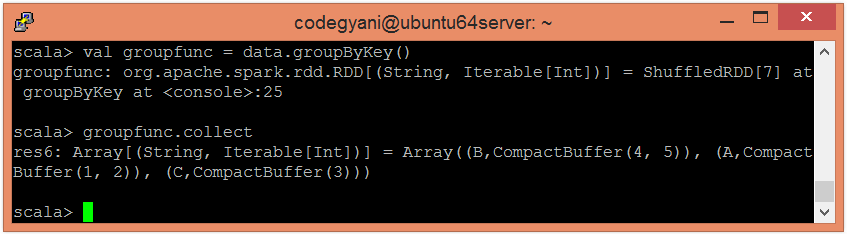
Here, we got the desired output.
Next TopicSpark reducedByKey Function